Recent work has explored the idea that the internal representations of LLMs (i.e. the way internal activations are represented in terms of features) lie on higher dimensional manifolds called feature manifolds. Geometric properties of these manifolds might tell us something about the properties of feature representations of a model.
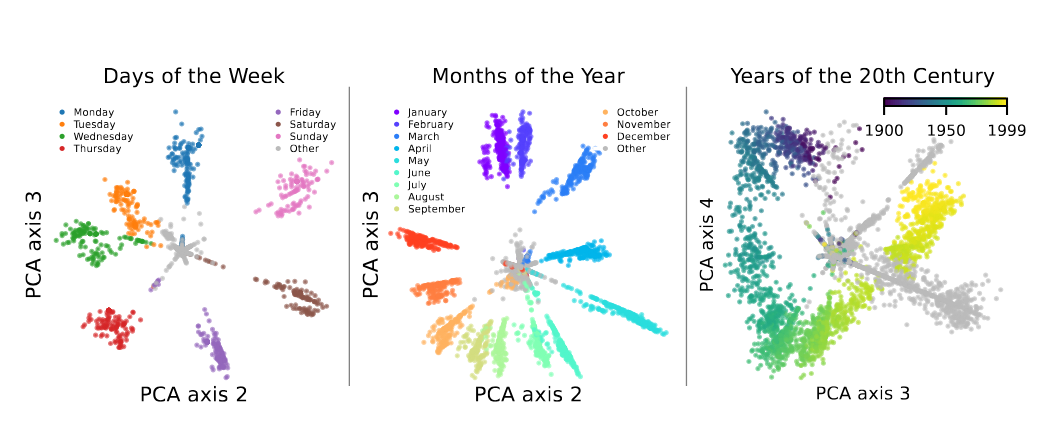
Figure 1:Features corresponding to the days of the week, months of the year, and years of the 20th century in layer 7 of GPT2-small appear to lie on a circle. The representations are obtained using an SAE and examing reconstructions after ablating all other SAE features, e.g. the points for days of the week are obtained by examining the representation of weekdays after passing through an SAE where all features are set to 0 except for the feature corresponding to weekdays (and a cluster that are closely related). Taken from Engels et al. (2024).
For instance Engels et al. (2024),discover that representations of certain concepts lie on higher dimensional manifolds inclusing features corresponding to the days of the week as depicted in Figure 1. Mathematically, we need to update what we mean by features in order to discuss these multi-dimensional features.
Multidimensional Features¶
A higher dimensional feature, might just be the sum of independent lower-dimensional features. We need a means of excluding such features.
An example of a separable distribution is geographical coordinates, which can be separated as latitude and longititude. A typical example of a mixture is a one-hot encoding which can be clearly expressed as a sum of lower dimensional features, where we get a Dirac measure on the points that are “hot”. Engels et al. (2024) operationalize both these criteria as the separability index and -mixture index respectively. Rather than going into the details here, the reader is referred to the paper. Instead, we sketch how one can update the superposition hypothesis to accomodate for multidimensional features and how the authors operationalize this using SAEs.
Discovering Multidimensional Features using SAEs¶
Can we use the machinery of SAEs that we built up to discover multidimensional features? Yes, by clustering the feature direction! Recall that features live in some higher dimensional spaqce and the model projects these down to a lower dimensional space (superposition hypothesis). Column of the decoder matrix of an SAE can be thought of as the projection of the basis vector of down to the lower dimensional space.
Consider a complete weighted graph whose nodes are features (i.e. one node for each column of the decoder matrix) and the weight of the edge connecting nodes and is simply the cosine similarity between the corresponding columns of the decoder matrix (i.e. a high edge weight says that the two features encode similar concepts). Set a threshold and prune edges with weight below . We now cluster the columns of by creating a cluster for each connected component of the graph. Note that the spaces spanned by each cluster are approximately -orthogonal (since all of the vectors in the cluster have cosine-similarity above ).
The claim is that if the SAE is large enough and is active enough (it activates on sufficiently large proportion of tokens), one of the clusters is likely to span . Consider an irreducible 2d feature and suppose includes just two columns , spanning , then these elements both must have nonzero activations (i.e. and for all in the subset of where is active) to reconstruct (otherwise is a mixture). Because of the sparsity penalty in (4), this two-vector solution to reconstruct is disincentivized, so instead the dictionary is likely to learn many elements that span . These dictionary elements will then have a high cosine similarity, and so the edges between them will not be pruned away during the clustering process; hence, they will be in a cluster.
While Example 1 provide examples that validates this framework, it is unclear why we do not discover more irreducible multidimensional features.
Modell et al. (2025) takes this formalism one step further and formally frames representations of features as manifolds. They recover the days of the week feature presented in Engels et al. (2024) as well as additional examples of 2 dimensional representation manifolds such as names of colors.
- Engels, J., Michaud, E. J., Liao, I., Gurnee, W., & Tegmark, M. (2024). Not All Language Model Features Are One-Dimensionally Linear. arXiv. 10.48550/ARXIV.2405.14860
- Modell, A., Rubin-Delanchy, P., & Whiteley, N. (2025). The Origins of Representation Manifolds in Large Language Models. arXiv. 10.48550/ARXIV.2505.18235